
DeepSeek-R1 es una familia de modelos de lenguaje de gran escala (LLMs) cuyo objetivo principal es mejorar las capacidades de razonamiento y generar respuestas más cercanas al contexto humano. Para ello, se basa en distintas etapas de Reinforcement Learning (Aprendizaje por refuerzo o RL) y, opcionalmente, en Supervised Fine-Tuning (SFT). Una de sus variantes, DeepSeek-R1-Zero, demuestra que es posible conseguir un modelo de razonamiento únicamente mediante técnicas de RL, incluso sin una fase previa de ajuste supervisado. Esto abre la puerta a nuevos enfoques en el entrenamiento de LLMs, reduciendo la dependencia de grandes volúmenes de datos etiquetados.
Este artículo explora cómo el uso de cadenas de pensamiento (Chain of Thought), la configuración del Reward Modeling y el propio proceso de RL han llegado a producir unas métricas tan buenas en DeepSeek-R1. También se aborda el fenómeno del “aha moment” y cómo, a través de la destilación, se puede transferir el razonamiento adquirido a modelos más pequeños sin perder efectividad.
Tipos de modelos de DeepSeek R1
El pasado 20 de enero DeepSeek lanzó sus modelos DeepSeek-R1 y DeepSeek-R1-Zero. Dos nuevos modelos de razonamiento que consiguen mejorar los resultados de OpenAI o1 en algunos benchmarks.
En palabras de los desarrolladores (Extracto extraído del paper):
DeepSeek-R1-Zero, es un modelo entrenado mediante aprendizaje por refuerzo (RL) a gran escala sin ajuste supervisado (SFT) como paso preliminar, demostrando capacidades de razonamiento notables. A través de RL, DeepSeek-R1-Zero ha desarrollado comportamientos de razonamiento potentes e intrigantes. Sin embargo, enfrenta desafíos como una lectura deficiente y mezcla de idiomas. Para abordar estos problemas y mejorar aún más el rendimiento del razonamiento, presentamos DeepSeek-R1, que incorpora entrenamiento en múltiples etapas y datos de inicio en frío antes de RL. DeepSeek-R1 logra un rendimiento comparable a OpenAI-gpt-4-1217 en tareas de razonamiento. Para apoyar a la comunidad investigadora, hacemos de código abierto DeepSeek-R1-Zero, DeepSeek-R1 y seis modelos densos (1.5B, 7B, 8B, 14B, 32B, 70B) destilados de DeepSeek-R1 basados en Qwen y Llama.
Estas son las principales diferencias entre ellos:
Entrenamiento
- DeepSeek-R1: Modelo de razonamiento que combina técnicas de Reinforcement Learning y Supervised Fine-Tuning. Se basa en datos supervisados para mejorar la coherencia y exactitud de sus respuestas.
- DeepSeek-R1-Zero: Modelo de razonamiento que se entrena únicamente con Reinforcement Learning, sin una fase previa de ajuste supervisado. Demuestra que es posible desarrollar habilidades de razonamiento desde cero con incentivos adecuados.
Fortalezas
- DeepSeek-R1: Ofrece respuestas más precisas y coherentes, especialmente en problemas matemáticos y de programación. Su fase de ajuste supervisado le permite alcanzar niveles de exactitud superiores. Esto lo está haciendo competir con modelos de razonamiento como o1 de OpenAI.
- DeepSeek-R1-Zero: Es capaz de generar razonamientos de manera creativa para resolver problemas. Es capaz de verificarse a sí mismo y reflexionar sus procesos haciendo uso de una cadena de pensamientos efectiva.
Debilidades
- DeepSeek-R1: Sus resultados no son tan creativos y pueden ser menos precisos en problemas complejos. Su dependencia de datos supervisados limita su escalabilidad y adaptabilidad.
- DeepSeek-R1-Zero: El modelo suele tender a generar respuestas menos precisas o mezclar idiomas. El resultado puede no ser tan amigable ya que no cuenta con un ajuste supervisado e incluso puede ser no interpretable.
¿Cómo funciona DeepSeek R1?
Chain of Thought: Cómo se estructuran las cadenas de pensamiento
El concepto de Chain of Thought (CoT) consiste en revelar, al menos internamente, los pasos de razonamiento que lleva a cabo el modelo antes de dar una respuesta final. Este proceso es la base para el enfoque de DeepSeek-R1, ya que:
- Facilita la retroalimentación: Al forzar al modelo a exponer su proceso de pensamiento, es posible evaluar la coherencia de sus pasos intermedios y dirigir la optimización a través de aprendizaje por refuerzo.
- Permite la corrección temprana: Si en algún paso el modelo comete un error, la próxima ronda de entrenamiento —o incluso el propio modelo— puede detectarlo y ajustarlo antes de ofrecer la respuesta final.
- Fomenta la reflexión: El propio modelo “aprende a pensar en voz alta”, lo cual a menudo conduce a soluciones más robustas.
Básicamente se trata de un truco de Prompt Engineering que permite al modelo generar respuestas más coherentes y precisas, al tiempo que facilita la retroalimentación y el ajuste de su proceso de razonamiento.
Es importante no confundir el system prompting con el Chain of Thought. El primero se refiere a la técnica de entrenamiento que consiste en guiar al modelo a través de una serie de pasos para que genere una respuesta coherente. Mientras que el segundo se refiere a la estructura interna de los pasos de razonamiento que sigue el modelo antes de ofrecer una respuesta final.
Esta es la plantilla de prompt que ha seguido DeepSeek R1 para conseguirlo tal y como muestran en su paper. Además etiquetamos las respuestas en dos: think y answer.
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: **prompt**. Assistant:Ejemplo de Chain of Thought para la pregunta “¿Hay más puertas o sillas en el mundo?”:
Respuesta de o1:
<think>
1. Hay millones de edificios en el mundo, y cada uno puede tener varias puertas internas y externas.
2. A la vez, casi todas las casas, oficinas, escuelas, tienen múltiples sillas.
3. En una casa típica, quizá haya un promedio de 5 a 10 puertas (entrada principal, interiores, armarios, etc.), mientras que en la misma casa podría haber un promedio de 4 a 8 sillas.
4. Sin embargo, existen también espacios comerciales y hoteles con muchas puertas, y lugares con muchos asientos (estadios, restaurantes).
5. Muchos edificios grandes pueden tener centenares de puertas, pero también centenares de sillas (salas de conferencia, cafeterías, etc.).
6. Comparar estos totales es complejo, pero la mayoría de estimaciones informales tiende a pensar que hay más puertas, considerando que incluso puertas de armarios, vehículos y otros espacios cuentan.
7. Podría ser muy cercano, pero la tendencia popular señala que las puertas podrían superar al número de sillas, dado que cada hogar y cada coche añade un número considerable de puertas.
</think>Respuesta final: Posiblemente haya más puertas que sillas en el mundo.Respuesta de DeepSeek R1:
<think>
Okay, so the question is whether there are more doors or chairs in the world.
Hmm, interesting. Let me try to break this down.
First, I need to think about where doors and chairs are commonly found. Doors
are part of buildings, right? Every house, apartment, office, school, hospital,
etc., has multiple doors. Even things like closets, bathrooms, and cabinets have
doors. So, in a typical house, there might be several doors. For example, maybe
each room has a door, plus doors for the front and back, maybe a garage door,
and then all the little doors on cabinets and wardrobes. That adds up.
Chairs, on the other hand, are also pretty common. Every home has chairs around
the dining table, maybe a few in the living room, offices have chairs for desks,
schools have chairs in classrooms, restaurants, theaters, stadiums... But wait,
some places might have more chairs than doors. Like a movie theater has a lot of
seats (which are chairs) but maybe only a few doors. Similarly, a school
classroom might have 30 chairs but just one or two doors. So maybe chairs are
more concentrated in certain areas.
But then again, think about all the cabinets, closets, and small compartments
that have doors. Each kitchen might have a dozen cabinet doors. In a hotel,
every room has a door, and each room might have a couple of chairs. But maybe
hotels have more doors because each room has a door, and each bathroom within
the room has a door, plus closet doors. So for each guest room, maybe 3-4 doors
but only 1-2 chairs. So in that case, doors might outnumber chairs.
Also, consider vehicles. Cars have doors (usually 4 per car) and seats. But
seats in cars are chairs? Maybe. So a car has 4 doors and, say, 5 seats. So
here, chairs (seats) outnumber doors. But how many cars are there globally?
There are over a billion cars, so that's a lot of seats. But then, trucks,
buses, trains, airplanes—all have seats and doors. So maybe in vehicles, chairs
(seats) are more numerous than doors. For example, a bus might have 2 doors but
40 seats. So that's a big difference.
But then again, in terms of buildings, especially residential buildings, maybe
doors are more. For example, a typical house might have 10 doors (front, back,
bedrooms, bathroom, closets, cabinets) and maybe 6 chairs. So doors would
outnumber chairs there. But in an office building, maybe each office has a
door, but each desk has a chair. So if there are many offices with doors and
each person has a chair, maybe chairs outnumber doors there. Hmm.
Then there's the question of industrial and commercial spaces. Factories might
have large doors for loading docks but also many chairs in break rooms or
offices. But maybe not as many chairs as doors? Or maybe more?
Also, think about public infrastructure. Public restrooms have multiple stalls
with doors. Each stall has a door, but how many chairs? Maybe just one or none.
So in restrooms, doors (stall doors) might outnumber chairs.
Another angle: consider temporary chairs. Events like concerts or conferences
set up temporary chairs, but those are not permanent. Do those count? The
question is about the world, so maybe all existing chairs, including temporary
ones. But doors are generally permanent fixtures. However, temporary structures
might have temporary doors as well, like portable toilets or pop-up shops. Not
sure if that's significant.
Also, in many parts of the world, especially in developing countries, some
homes might have fewer chairs. For example, in some cultures, people might sit
on the floor more, so fewer chairs. But they would still have doors. So that
might tip the balance towards doors.
Additionally, think about all the appliances and furniture that have small
doors, like refrigerators, microwaves, ovens, washing machines. Each of those
has a door. So even in a kitchen, you might have several appliance doors plus
cabinet doors. Each of those counts as a door. Meanwhile, chairs are only the
seats people sit on.
Wait, but chairs can be stacked or stored. For example, a school might have a
storage room with hundreds of chairs for events. So even if they're not in use,
they exist. Similarly, restaurants might have extra chairs. So chairs can be
stored in large numbers.
But doors are part of the structure. Once a building is built, the doors are
fixed. Unless you have a lot of cabinets and closets, which many buildings do.
So maybe the sheer number of cabinet doors in homes and offices adds up to a
huge number.
Let me try to estimate roughly. Let's say the global population is around 8
billion. Assume each person has a certain number of doors and chairs in their
living environment.
For doors: If each person has, say, 10 doors (considering homes, workplaces,
schools, etc.), that would be 80 billion doors. But that might be high.
Alternatively, think of the number of buildings. There are roughly 2 billion
households worldwide. If each household has, on average, 10 doors (including
interior doors, cabinets, etc.), that's 20 billion doors. Then add doors from
commercial buildings, offices, schools, hospitals, vehicles, etc. Maybe the
total is in the tens of billions.
For chairs: Each household might have, say, 6 chairs. So 2 billion households
would have 12 billion chairs. Then add chairs in offices (each office worker
has a chair), schools (each student has a chair), public places like
restaurants, theaters, etc. Also, vehicles contribute seats as chairs. If there
are over a billion cars, each with 5 seats, that's 5 billion chairs. Then
buses, trains, planes add more. Maybe total chairs are around 20-30 billion?
Not sure.
If chairs are around 25 billion, then doors would be more. But I'm not sure if
my estimates are accurate. Maybe cabinet doors are overcounted. Do we consider
small cabinet doors as "doors" in this context? The question is in Spanish,
"puertas", which typically refers to larger doors like room doors, but maybe it
includes any door, even small ones. If yes, then cabinet doors count, which
would significantly increase the number.
Alternatively, maybe the original question is considering only doors that lead
into rooms or buildings, not small cabinet doors. That would change the
calculation. But the user didn't specify, so I have to assume all types of
doors.
In conclusion, it's a close call, but considering all types of doors (including
cabinets, appliances, vehicles), doors probably outnumber chairs globally.
</think>Respuesta final:
Probablemente hay más puertas que sillas en el mundo, gracias a su presencia en estructuras grandes y pequeñas, vehículos y electrodomésticos.Este “razonamiento paso a paso” muestra cómo se va desengranando la lógica antes de llegar a una respuesta, lo cual es fundamental para el entrenamiento a través de RL.
Reinforcement Learning
DeepSeek-R1-Zero ejemplifica la aplicación directa de RL al modelo base, sin una etapa previa de ajuste supervisado. El enfoque se fundamenta en que, con los incentivos adecuados (recompensas por exactitud y formato), el modelo:
- Experimenta con diversas estrategias de solución (ej., probar distintos estilos de razonamiento).
- Recibe retroalimentación inmediata en forma de “recompensa” cuando sus respuestas cumplen criterios de exactitud o formato.
- Para ello se utilizan algoritmos como Group Relative Policy Optimization (GRPO), que reduce costos de cómputo al estimar la base (baseline) de la política mediante una agrupación de ejemplos de salida en lugar de contar con un critic del mismo tamaño que el modelo.
Las puntos claves del algoritmo GRPO son:
- El modelo genera un grupo de respuestas
- Se evalúa la recompensa de cada respuesta
- Se calcula la recompensa media del grupo
- Se calcula la diferencia entre la recompensa de cada respuesta y la media
- Se actualiza el modelo con la diferencia de recompensa
- La respuesta es la que ha obtenido la mayor recompensa
- El proceso se repite permitiendo al modelo aprender y mejorar a lo largo del tiempo
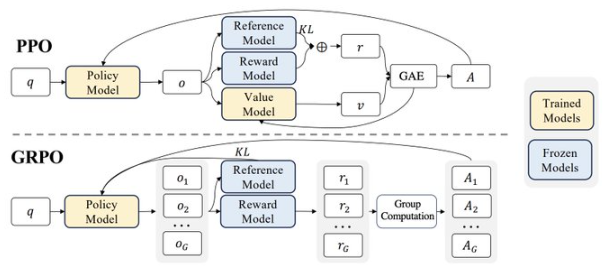
Reward Modeling
Para entrenar DeepSeek-R1, se definen los siguientes tipos de recompensas:
-
Accuracy Rewards (exactitud):
- Verifica la corrección de la respuesta a un problema matemático a través de la comparación con el resultado esperado.
- En problemas de programación (LeetCode), se compila el código y se verifica contra tests predefinidos.
-
Format Rewards (formato):
- Se recompensa al modelo por incluir su proceso de razonamiento entre etiquetas como think.
- Esto garantiza la trazabilidad de los pasos de razonamiento.
No se emplea un "Outcome" o "Process Neural Reward Model" en la etapa inicial de DeepSeek-R1-Zero para evitar el reward hacking y la complejidad de entrenar una red neuronal adicional.
Distillation
El proceso de distilación busca transferir las habilidades de razonamiento adquiridas por DeepSeek-R1 (u otros modelos grandes) hacia modelos más pequeños, conservando su desempeño:
- Se generan datos de razonamiento (CoT) utilizando el modelo grande.
- Se entrena un modelo más pequeño para imitar esos patrones de razonamiento y respuesta.
- Se logran resultados competitivos sin requerir la misma potencia computacional y recursos de entrenamiento que el modelo grande.
DeepSeek-R1 ha compartido abiertamente checkpoints destilados para varios tamaños de modelos (1.5B, 7B, 8B, 14B, 32B y 70B), basados en la familia Qwen2.5 y Llama3. Esto facilita a la comunidad aprovechar estas técnicas de distilación y construir soluciones más ligeras y accesibles. Permitiendo ejecutarlo en diferentes dispositivos.
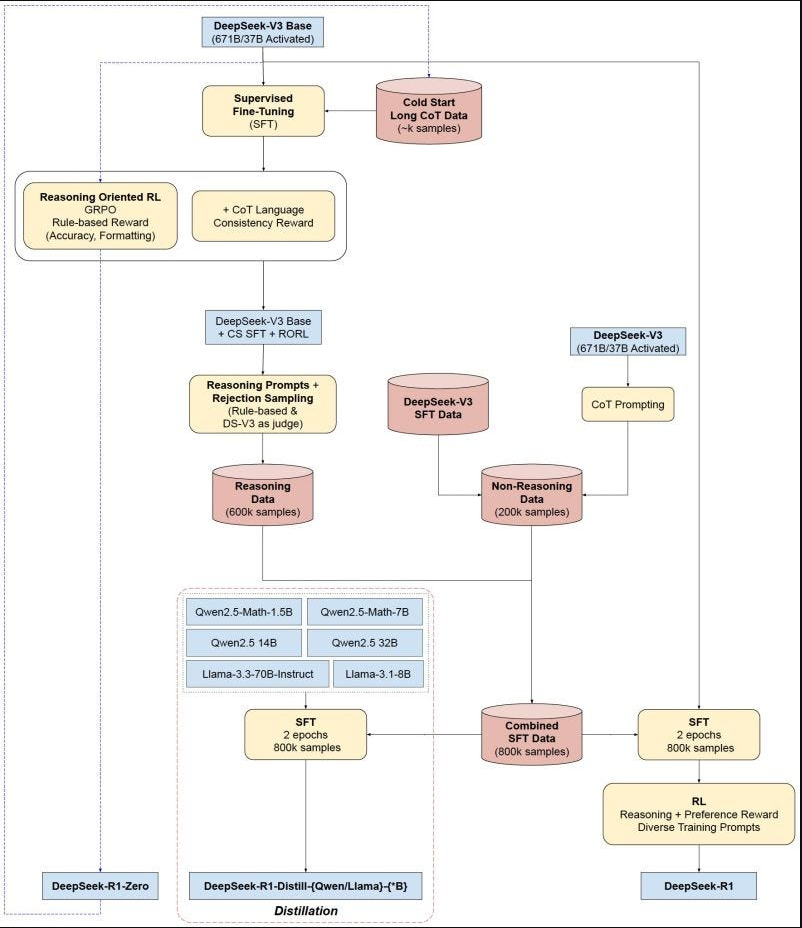
Aha Moment
Uno de los hallazgos más interesantes durante la fase de entrenamiento de DeepSeek-R1-Zero es el surgimiento de un fenómeno conocido como “aha moment”. En esta etapa intermedia:
- El modelo “descubre” que dedicar más pasos de razonamiento a un problema le proporciona mejores recompensas.
- Practica la reevaluación de su respuesta inicial, corrigiendo errores y afinando la solución final.
Para los investigadores, este momento destaca la belleza y el poder de RL, ya que no se le enseña explícitamente la estrategia paso a paso, sino que el modelo la crea al recibir recompensas bien diseñadas.

Perfomance de DeepSeek R1
Los resultados de rendimiento de DeepSeek-R1 y sus variantes son notables:
- DeepSeek-R1-Zero muestra que el razonamiento puede emerger desde cero usando solo RL.
- DeepSeek-R1 (versión con datos supervisados) logra aún mayores niveles de coherencia y exactitud, especialmente en problemas complejos de matemáticas y programación.
- Se han reportado incrementos de desempeño en benchmarks como AIME 2024, MATH-500 y LiveCodeBench.
- Entre las versiones más destacadas se encuentra DeepSeek-R1-Distill-Qwen-7B, que supera a modelos mucho más grandes en pruebas específicas, y DeepSeek-R1-Distill-Qwen-32B, con resultados sobresalientes en MATH-500 y LiveCodeBench.
Estas cifras demuestran un gran avance respecto a modelos previos de código abierto, demostrando la eficacia de la combinación de RL y razonamiento explícito.
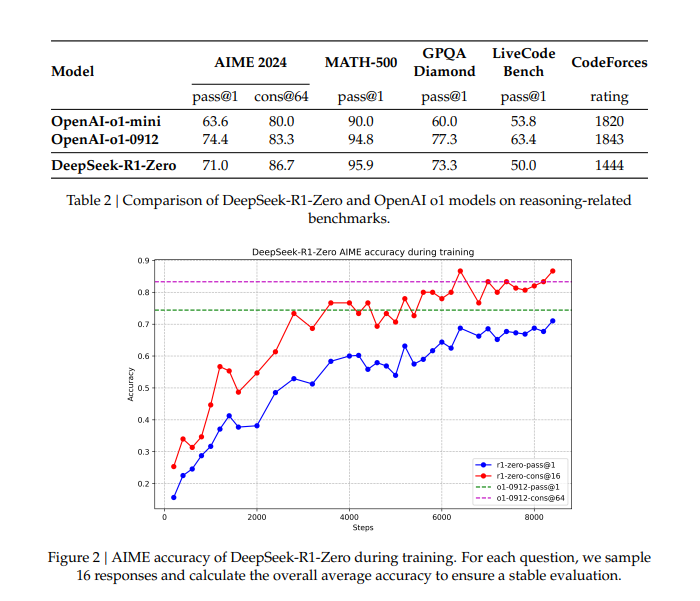
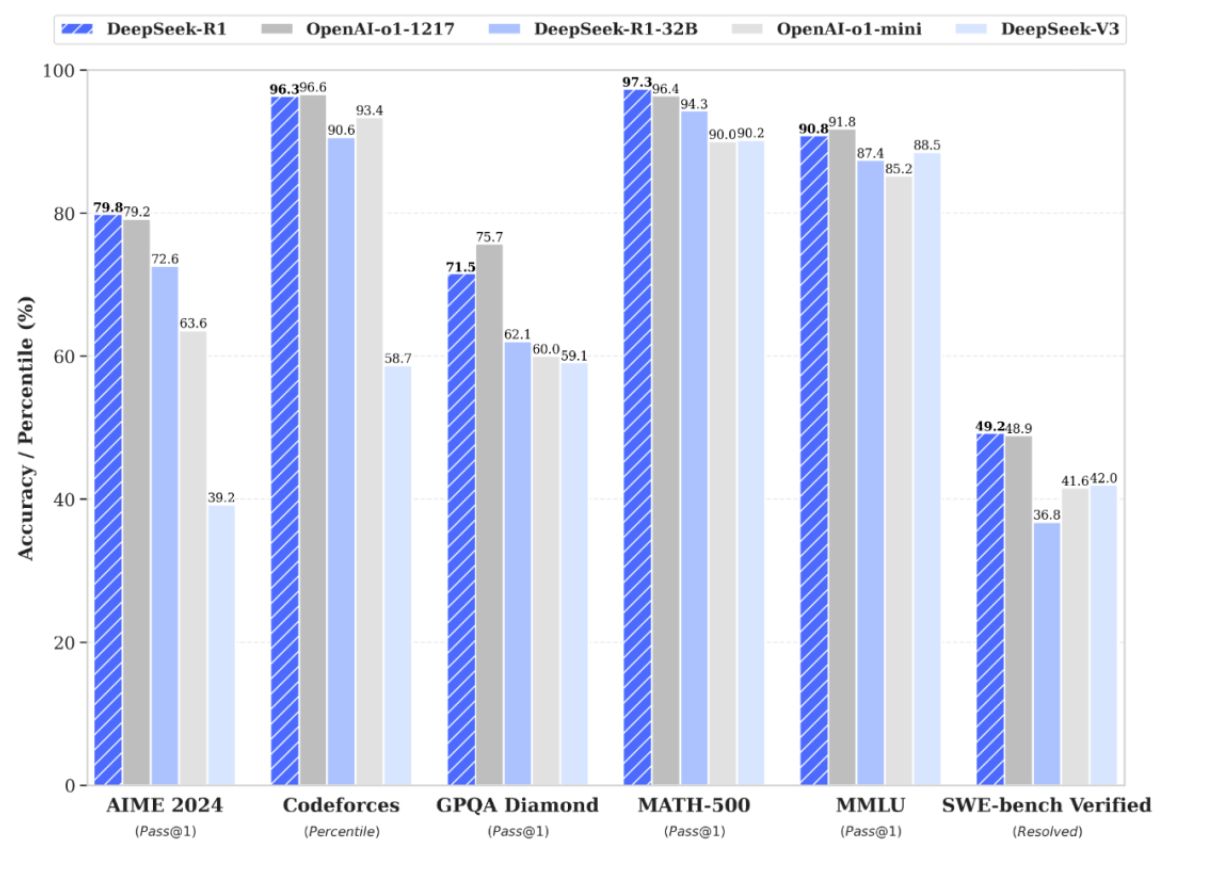
Consecuencias del lanzamiento del modelo DeepSeek R1
El lanzamiento de DeepSeek-R1 y DeepSeek-R1-Zero ha provocado un gran impacto en la comunidad de investigación y desarrollo de LLMs. Algunas de las consecuencias más destacadas son:
- Disminución de la dependencia en datos supervisados: Se demuestra que modelos de gran escala pueden desarrollar habilidades de razonamiento solo mediante incentivos de RL, sin necesidad de una fase extensiva de SFT. Esto ha sido provocado por las limitaciones de EEUU que impone sobre China. El equipo de DeepSeek R1 se ha visto obligado a redescubrir nuevas técnicas para poder conseguir el mismo o mejor rendimiento que modelos como O1 de OpenAI pero con muchísima menos potencia de tarjetas gráficas.
- Automatización de estrategias de razonamiento: Al no estar “anclado” por datos supervisados que impongan un estilo fijo de resolver problemas, el modelo puede descubrir tácticas de solución creativas.
- Facilidad de adopción en entornos con datos limitados: Muchos sectores industriales cuentan con datos sensibles o escasos; la capacidad de entrenar un modelo a partir de un mínimo de supervisión es un gran paso hacia la escalabilidad y adaptabilidad.
- Surgimiento de comportamientos emergentes: El “aha moment” es un ejemplo destacado de la forma en que los modelos, incentivados adecuadamente, pueden desarrollar estrategias de razonamiento sorprendentes.
Esto se ha traducido en:
- Caída en bolsa de compañías tecnológicas: En los últimos meses, empresas como OpenAI, Meta o Microsoft han tenido inversiones de capital sin límites. Por tanto, cuando ha aparecido un competidor de muchísima calidad que ha conseguido resultados con una inversión muy reducida, los inversores han perdido su expectativa de crecimiento provocando una fuerte caída en bolsa de estas compañías por un valor de más de 600.000 millones de dólares.
- Aumento de la inversión en modelos de razonamiento: China ha anunciado una inversión de más de 137.000 millones de dólares en el desarrollo de modelos de razonamiento. Lo que fomentará la competencia y la innovación en este campo.
- Crítica sobre las sanciones de EEUU a China: Son muchos desarrolladores y directivos los que han puesto en duda que se estén cumpliendo las sanciones sobre China y piden un mayor control o limitar aún más el número de tarjetas gráficas a las que pueden acceder.
Conclusión
La carrera por conseguir la AGI (Inteligencia Artificial General) ha comenzado y nadie quiere quedarse atrás. Estamos viviendo un momento de gran innovación y competencia que tiene el potencial de cambiar la humanidad y nuestro día a día.
En ocasiones, la limitación de recursos puede ser una oportunidad para descubrir nuevas técnicas y enfoques. DeepSeek R1 es un claro ejemplo de cómo, con incentivos adecuados y un enfoque innovador, es posible desarrollar modelos de razonamiento que compitan con desarrollos de meses de trabajo y millones de dólares de inversión.
¿Qué pasaría si estos científicos y desarrolladores tuvieran acceso a los mismos recursos que OpenAI o Meta? ¿Qué modelos podrían desarrollar? ¿Qué problemas podrían resolver? ¿Qué impacto tendría en la sociedad?
Se ha mencionado mucho que la burbuja de la IA ha explotado y que estamos en un momento de crisis. Pero, ¿realmente es una crisis o es una oportunidad para que compañías más pequeñas vean que también tiene la posibilidad de formar parte de la carrera a la AGI?
Si la AGI es un beneficio o un peligro para la humanidad, solo el tiempo lo dirá. Por ahora, disfrutemos los avances y la competencia que nos llevan a un futuro más inteligente y prometedor.


