
DeepSeek-R1 is a family of large-scale language models (LLMs) whose primary goal is to enhance reasoning capabilities and generate responses that are more aligned with human context. To achieve this, it relies on various stages of Reinforcement Learning (RL) and, optionally, Supervised Fine-Tuning (SFT). One of its variants, DeepSeek-R1-Zero, demonstrates that it is possible to develop a reasoning model solely through RL techniques, even without a prior supervised fine-tuning phase. This paves the way for new approaches to training LLMs, reducing dependence on large volumes of labeled data.
This article explores how the use of Chain of Thought reasoning, Reward Modeling configuration, and the RL process itself have contributed to DeepSeek-R1 outstanding performance metrics. It also delves into the phenomenon of the “aha moment” and how, through distillation, the acquired reasoning can be transferred to smaller models without losing effectiveness.
Types of DeepSeek R1 Models
On January 20, DeepSeek released its DeepSeek-R1 and DeepSeek-R1-Zero models—two new reasoning models that outperform OpenAI o1 in some benchmarks.
In the words of the developers (Excerpt from the paper):
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities.Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguingreasoning behaviors. However, it encounters challenges such as poor readability, and languagemixing. To address these issues and further enhance reasoning performance, we introduceDeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeekR1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks. To support theresearch community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models(1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
Here are the main differences between them:
Training
- DeepSeek-R1: A reasoning model that combines Reinforcement Learning and Supervised Fine-Tuning techniques. It relies on supervised data to improve response coherence and accuracy.
- DeepSeek-R1-Zero: A reasoning model trained solely with Reinforcement Learning, without a prior supervised fine-tuning phase. It proves that reasoning abilities can be developed from scratch with the right incentives.
Strengths
- DeepSeek-R1: Provides more accurate and coherent responses, especially in mathematical and programming problems. Its supervised fine-tuning phase allows it to achieve higher levels of accuracy, putting it in competition with reasoning models like OpenAI’s o1.
- DeepSeek-R1-Zero: Capable of generating creative reasoning to solve problems. It can self-verify and reflect on its processes by using an effective Chain of Thought mechanism.
Weaknesses
- DeepSeek-R1: Its results are less creative and may be less precise in complex problems. Its reliance on supervised data limits its scalability and adaptability.
- DeepSeek-R1-Zero: The model tends to generate less precise responses or mix languages. The output may be less user-friendly as it lacks supervised fine-tuning and can even be difficult to interpret.
How Does DeepSeek R1 Work?
Chain of Thought: Structuring Thought Processes
The concept of Chain of Thought (CoT) involves revealing, at least internally, the reasoning steps the model takes before providing a final answer. This process is fundamental to DeepSeek-R1 approach because:
- It facilitates feedback: By forcing the model to expose its thought process, it becomes possible to evaluate the coherence of its intermediate steps and guide optimization through reinforcement learning.
- It allows for early correction: If the model makes an error in one step, the next training round—or even the model itself—can detect and adjust it before providing the final answer.
- It encourages reflection: The model “learns to think out loud,” often leading to more robust solutions.
Essentially, this is a Prompt Engineering technique that enables the model to generate more coherent and accurate responses while also making its reasoning process easier to refine and adjust.
It is important not to confuse system prompting with Chain of Thought. System prompting refers to a training technique that involves guiding the model through a series of steps to generate a coherent response, while the latter refers to the internal structure of the reasoning steps the model follows before producing a final answer.
This is the prompt template DeepSeek R1 has used to achieve this, as shown in their paper. Additionally, responses are labeled into two categories: think and answer.
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: **prompt**. Assistant:Example of Chain of Thought for the question “Are there more doors or chairs in the world?”:
Response from o1:
<think>
1. There are millions of buildings in the world, and each one can have multiple internal and external doors.
2. At the same time, almost all houses, offices, and schools contain multiple chairs.
3. In a typical house, there may be an average of 5 to 10 doors (main entrance, interior doors, closets, etc.), while the same house might have an average of 4 to 8 chairs.
4. However, there are also commercial spaces and hotels with many doors, as well as places with many seats (stadiums, restaurants).
5. Many large buildings can have hundreds of doors, but also hundreds of chairs (conference rooms, cafeterias, etc.).
6. Comparing these totals is complex, but most informal estimates tend to suggest that there are more doors, considering that even closet doors, vehicle doors, and other types of doors count.
7. It could be very close, but popular opinion leans towards the idea that there might be more doors than chairs, given that every home and every car adds a significant number of doors.
</think>Final answer: There are possibly more doors than chairs in the world.Response from DeepSeek R1:
<think>
Okay, so the question is whether there are more doors or chairs in the world.
Hmm, interesting. Let me try to break this down.
First, I need to think about where doors and chairs are commonly found. Doors
are part of buildings, right? Every house, apartment, office, school, hospital,
etc., has multiple doors. Even things like closets, bathrooms, and cabinets have
doors. So, in a typical house, there might be several doors. For example, maybe
each room has a door, plus doors for the front and back, maybe a garage door,
and then all the little doors on cabinets and wardrobes. That adds up.
Chairs, on the other hand, are also pretty common. Every home has chairs around
the dining table, maybe a few in the living room, offices have chairs for desks,
schools have chairs in classrooms, restaurants, theaters, stadiums... But wait,
some places might have more chairs than doors. Like a movie theater has a lot of
seats (which are chairs) but maybe only a few doors. Similarly, a school
classroom might have 30 chairs but just one or two doors. So maybe chairs are
more concentrated in certain areas.
But then again, think about all the cabinets, closets, and small compartments
that have doors. Each kitchen might have a dozen cabinet doors. In a hotel,
every room has a door, and each room might have a couple of chairs. But maybe
hotels have more doors because each room has a door, and each bathroom within
the room has a door, plus closet doors. So for each guest room, maybe 3-4 doors
but only 1-2 chairs. So in that case, doors might outnumber chairs.
Also, consider vehicles. Cars have doors (usually 4 per car) and seats. But
seats in cars are chairs? Maybe. So a car has 4 doors and, say, 5 seats. So
here, chairs (seats) outnumber doors. But how many cars are there globally?
There are over a billion cars, so that's a lot of seats. But then, trucks,
buses, trains, airplanes—all have seats and doors. So maybe in vehicles, chairs
(seats) are more numerous than doors. For example, a bus might have 2 doors but
40 seats. So that's a big difference.
But then again, in terms of buildings, especially residential buildings, maybe
doors are more. For example, a typical house might have 10 doors (front, back,
bedrooms, bathroom, closets, cabinets) and maybe 6 chairs. So doors would
outnumber chairs there. But in an office building, maybe each office has a
door, but each desk has a chair. So if there are many offices with doors and
each person has a chair, maybe chairs outnumber doors there. Hmm.
Then there's the question of industrial and commercial spaces. Factories might
have large doors for loading docks but also many chairs in break rooms or
offices. But maybe not as many chairs as doors? Or maybe more?
Also, think about public infrastructure. Public restrooms have multiple stalls
with doors. Each stall has a door, but how many chairs? Maybe just one or none.
So in restrooms, doors (stall doors) might outnumber chairs.
Another angle: consider temporary chairs. Events like concerts or conferences
set up temporary chairs, but those are not permanent. Do those count? The
question is about the world, so maybe all existing chairs, including temporary
ones. But doors are generally permanent fixtures. However, temporary structures
might have temporary doors as well, like portable toilets or pop-up shops. Not
sure if that's significant.
Also, in many parts of the world, especially in developing countries, some
homes might have fewer chairs. For example, in some cultures, people might sit
on the floor more, so fewer chairs. But they would still have doors. So that
might tip the balance towards doors.
Additionally, think about all the appliances and furniture that have small
doors, like refrigerators, microwaves, ovens, washing machines. Each of those
has a door. So even in a kitchen, you might have several appliance doors plus
cabinet doors. Each of those counts as a door. Meanwhile, chairs are only the
seats people sit on.
Wait, but chairs can be stacked or stored. For example, a school might have a
storage room with hundreds of chairs for events. So even if they're not in use,
they exist. Similarly, restaurants might have extra chairs. So chairs can be
stored in large numbers.
But doors are part of the structure. Once a building is built, the doors are
fixed. Unless you have a lot of cabinets and closets, which many buildings do.
So maybe the sheer number of cabinet doors in homes and offices adds up to a
huge number.
Let me try to estimate roughly. Let's say the global population is around 8
billion. Assume each person has a certain number of doors and chairs in their
living environment.
For doors: If each person has, say, 10 doors (considering homes, workplaces,
schools, etc.), that would be 80 billion doors. But that might be high.
Alternatively, think of the number of buildings. There are roughly 2 billion
households worldwide. If each household has, on average, 10 doors (including
interior doors, cabinets, etc.), that's 20 billion doors. Then add doors from
commercial buildings, offices, schools, hospitals, vehicles, etc. Maybe the
total is in the tens of billions.
For chairs: Each household might have, say, 6 chairs. So 2 billion households
would have 12 billion chairs. Then add chairs in offices (each office worker
has a chair), schools (each student has a chair), public places like
restaurants, theaters, etc. Also, vehicles contribute seats as chairs. If there
are over a billion cars, each with 5 seats, that's 5 billion chairs. Then
buses, trains, planes add more. Maybe total chairs are around 20-30 billion?
Not sure.
If chairs are around 25 billion, then doors would be more. But I'm not sure if
my estimates are accurate. Maybe cabinet doors are overcounted. Do we consider
small cabinet doors as "doors" in this context? The question is in Spanish,
"puertas", which typically refers to larger doors like room doors, but maybe it
includes any door, even small ones. If yes, then cabinet doors count, which
would significantly increase the number.
Alternatively, maybe the original question is considering only doors that lead
into rooms or buildings, not small cabinet doors. That would change the
calculation. But the user didn't specify, so I have to assume all types of
doors.
In conclusion, it's a close call, but considering all types of doors (including
cabinets, appliances, vehicles), doors probably outnumber chairs globally.
</think>Final answer:
There are probably more doors than chairs in the world, thanks to their presence in large and small structures, vehicles, and appliances.This “step-by-step reasoning” demonstrates how logic is broken down before reaching an answer, which is fundamental for RL-based training.
Reinforcement Learning
DeepSeek-R1-Zero exemplifies the direct application of RL to the base model without a prior supervised fine-tuning stage. The approach is based on the idea that, with the right incentives (rewards for accuracy and format), the model:
- Experiments with different solution strategies (e.g., testing various reasoning styles).
- Receives immediate feedback in the form of “rewards” when its responses meet accuracy or format criteria.
- Uses algorithms like Group Relative Policy Optimization (GRPO), which reduces computational costs by estimating the policy baseline through grouped output samples instead of requiring a critic model of the same size.
Key points of the GRPO algorithm:
- The model generates a set of responses.
- The reward for each response is evaluated.
- The average reward for the group is calculated.
- The difference between each response’s reward and the average is computed.
- The model is updated based on the reward difference.
- The highest-reward response is selected.
- The process repeats, allowing the model to learn and improve over time.
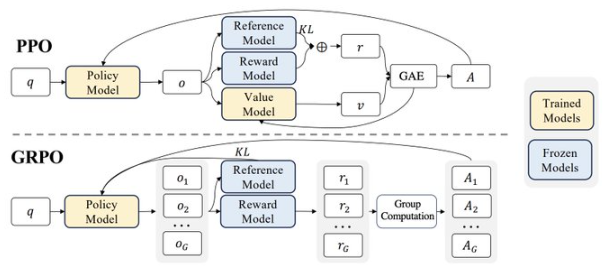
Reward Modeling
To train DeepSeek-R1, the following types of rewards are defined:
-
Accuracy Rewards:
- Verifies the correctness of mathematical problem solutions by comparing them to expected results.
- In programming problems (LeetCode), the code is compiled and checked against predefined test cases.
-
Format Rewards:
- Rewards the model for including its reasoning process within labels such as think.
- Ensures traceability of reasoning steps.
No "Outcome" or "Process Neural Reward Model" is employed in DeepSeek-R1-Zero's initial stage to prevent reward hacking and the complexity of training an additional neural network.
Distillation
The distillation process aims to transfer the reasoning capabilities acquired by DeepSeek-R1 (or other large models) to smaller models while maintaining performance:
- Reasoning data (CoT) is generated using the large model.
- A smaller model is trained to imitate these reasoning and response patterns.
- Competitive results are achieved without requiring the same computational power and training resources as the large model.
DeepSeek-R1 has openly shared distilled checkpoints for various model sizes (1.5B, 7B, 8B, 14B, 32B, and 70B), based on the Qwen2.5 and Llama3 families. This allows the community to leverage these distillation techniques and build lighter, more accessible solutions, enabling deployment across different devices.
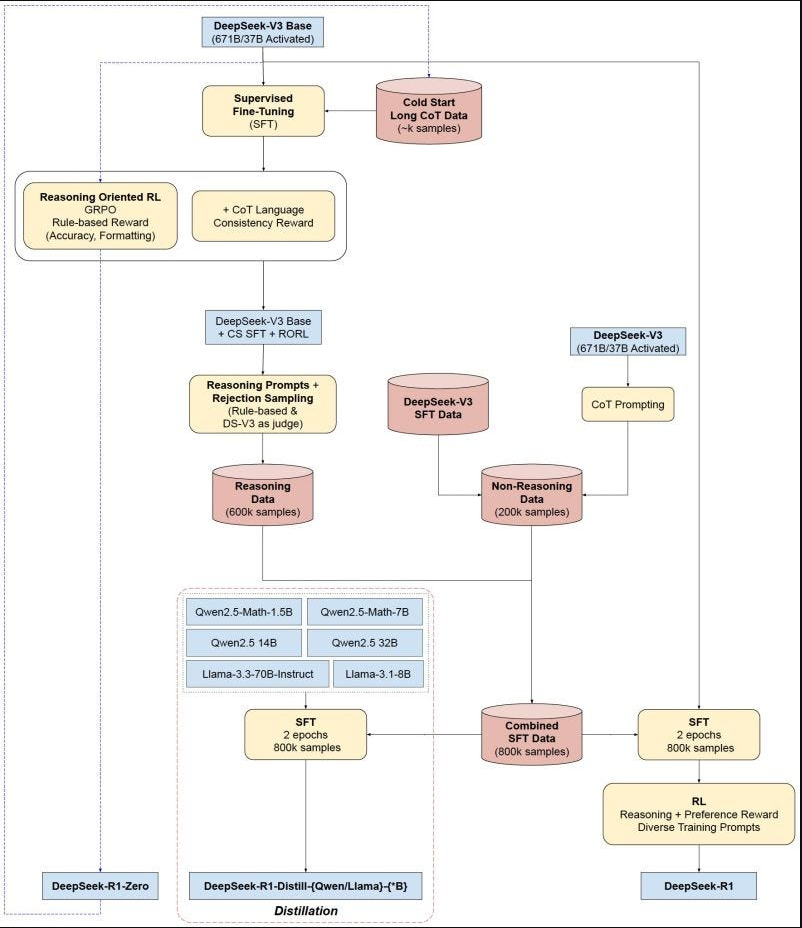
Aha Moment
One of the most interesting discoveries during DeepSeek-R1-Zero’s training phase is the emergence of a phenomenon known as the “aha moment.” In this intermediate stage:
- The model "realizes" that dedicating more reasoning steps to a problem yields better rewards.
- It practices re-evaluating its initial response, correcting mistakes, and refining the final solution.
For researchers, this moment highlights the beauty and power of RL, as the model is not explicitly taught a step-by-step strategy—it discovers it by receiving well-designed rewards.

Performance of DeepSeek R1
The performance results of DeepSeek-R1 and its variants are remarkable:
- DeepSeek-R1-Zero demonstrates that reasoning can emerge from scratch using only RL.
- DeepSeek-R1 (the supervised version) achieves even higher levels of coherence and accuracy, particularly in complex math and programming problems.
- Performance improvements have been reported in benchmarks such as AIME 2024, MATH-500, and LiveCodeBench.
- Among the standout versions is DeepSeek-R1-Distill-Qwen-7B, which surpasses much larger models in specific tests, and DeepSeek-R1-Distill-Qwen-32B, which achieves outstanding results in MATH-500 and LiveCodeBench.
These figures represent a significant advancement over previous open-source models, demonstrating the effectiveness of combining RL and explicit reasoning.
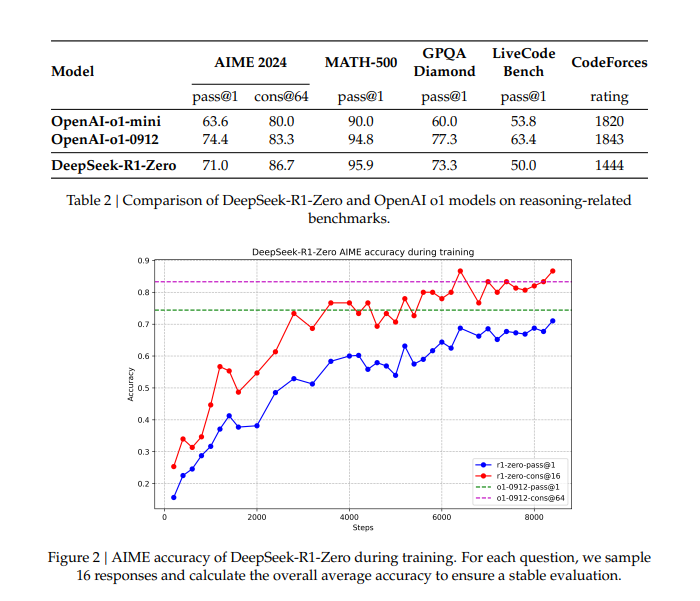
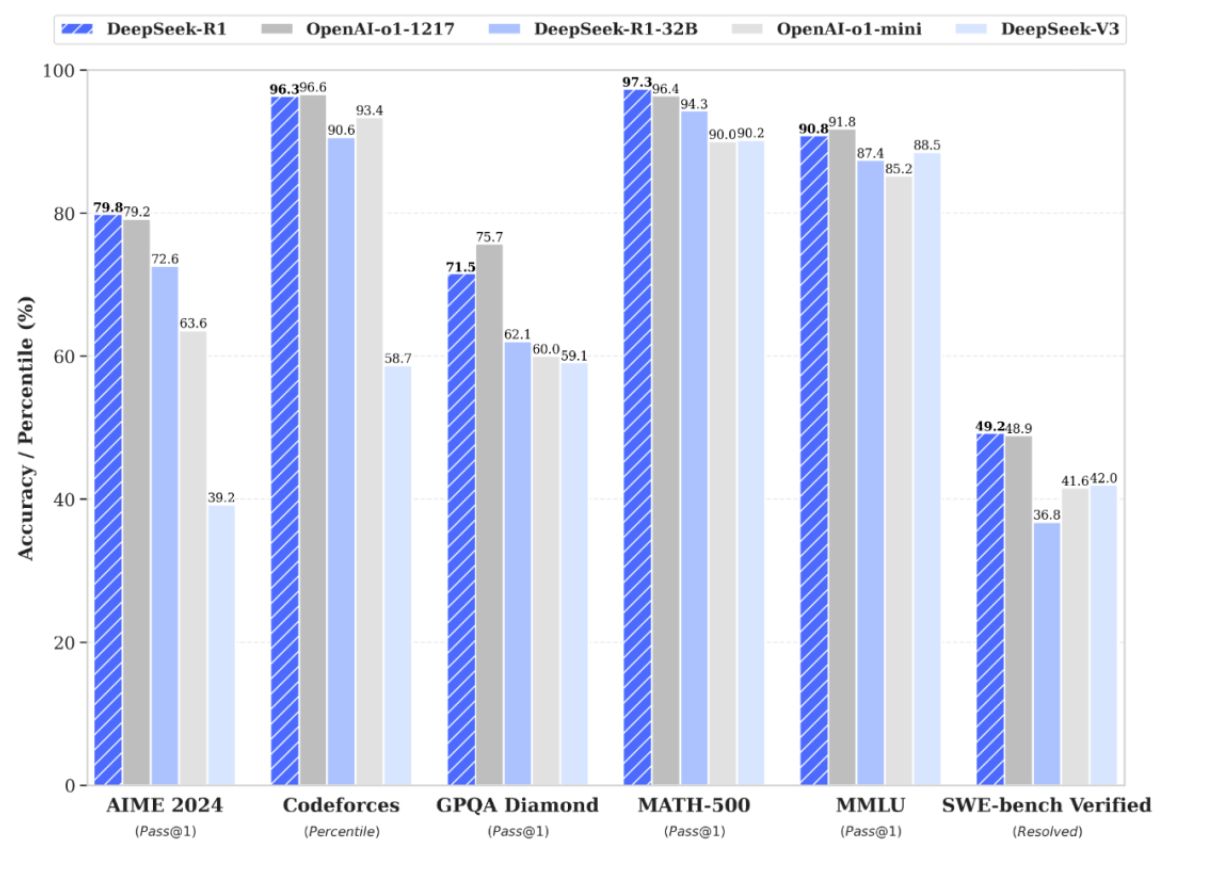
Consequences of the DeepSeek R1 Release
The release of DeepSeek-R1 and DeepSeek-R1-Zero has had a significant impact on the LLM research and development community. Some of the most notable consequences include:
- Reduced dependence on supervised data: It is now evident that large-scale models can develop reasoning abilities solely through RL incentives, without requiring extensive SFT. This has been influenced by U.S. restrictions on China, forcing the DeepSeek R1 team to discover new techniques to achieve performance comparable to OpenAI's O1 with significantly lower computational resources.
- Automation of reasoning strategies: Without being “anchored” by supervised data enforcing a fixed problem-solving style, the model can discover creative solution tactics.
- Easier adoption in data-limited environments: Many industries work with sensitive or scarce data; the ability to train a model with minimal supervision is a significant step toward scalability and adaptability.
- Emergent behaviors: The "aha moment" is a prime example of how models, when properly incentivized, can develop surprising reasoning strategies.
This has led to:
- Stock market declines in tech companies: In recent months, companies like OpenAI, Meta, and Microsoft have seen unlimited capital investments. However, the emergence of a high-quality competitor achieving results with a fraction of the investment has led investors to lose growth expectations, causing a market drop exceeding $600 billion for these companies.
- Increased investment in reasoning models: China has announced an investment of over $137 billion in the development of reasoning models, fostering competition and innovation in this field.
- Criticism of U.S. sanctions on China: Many developers and executives have questioned whether the sanctions against China are being effectively enforced and are calling for stricter controls or further limitations on GPU access.
Conclusion
The race to achieve AGI (Artificial General Intelligence) has begun, and no one wants to be left behind. We are witnessing a period of rapid innovation and competition with the potential to reshape humanity and our daily lives.
Sometimes, resource limitations can be an opportunity to discover new techniques and approaches. DeepSeek R1 is a clear example of how, with proper incentives and an innovative mindset, it is possible to develop reasoning models that rival months of research and millions of dollars in investment.
What would happen if these scientists and developers had the same resources as OpenAI or Meta? What models could they develop? What problems could they solve? What impact would they have on society?
Many have claimed that the AI bubble has burst and that we are in a crisis. But is this truly a crisis, or is it an opportunity for smaller companies to realize they, too, can participate in the race toward AGI?
Whether AGI is a benefit or a danger to humanity remains to be seen. For now, let's enjoy the advancements and competition that are leading us toward a smarter and more promising future.

